Our Research
Science drives everything we do. Here, you’ll find PURR.AI’s peer-reviewed publications, conference papers, and research collaborations. Each reflects our commitment to advancing AI-driven drug discovery and sharing knowledge with the global scientific community.
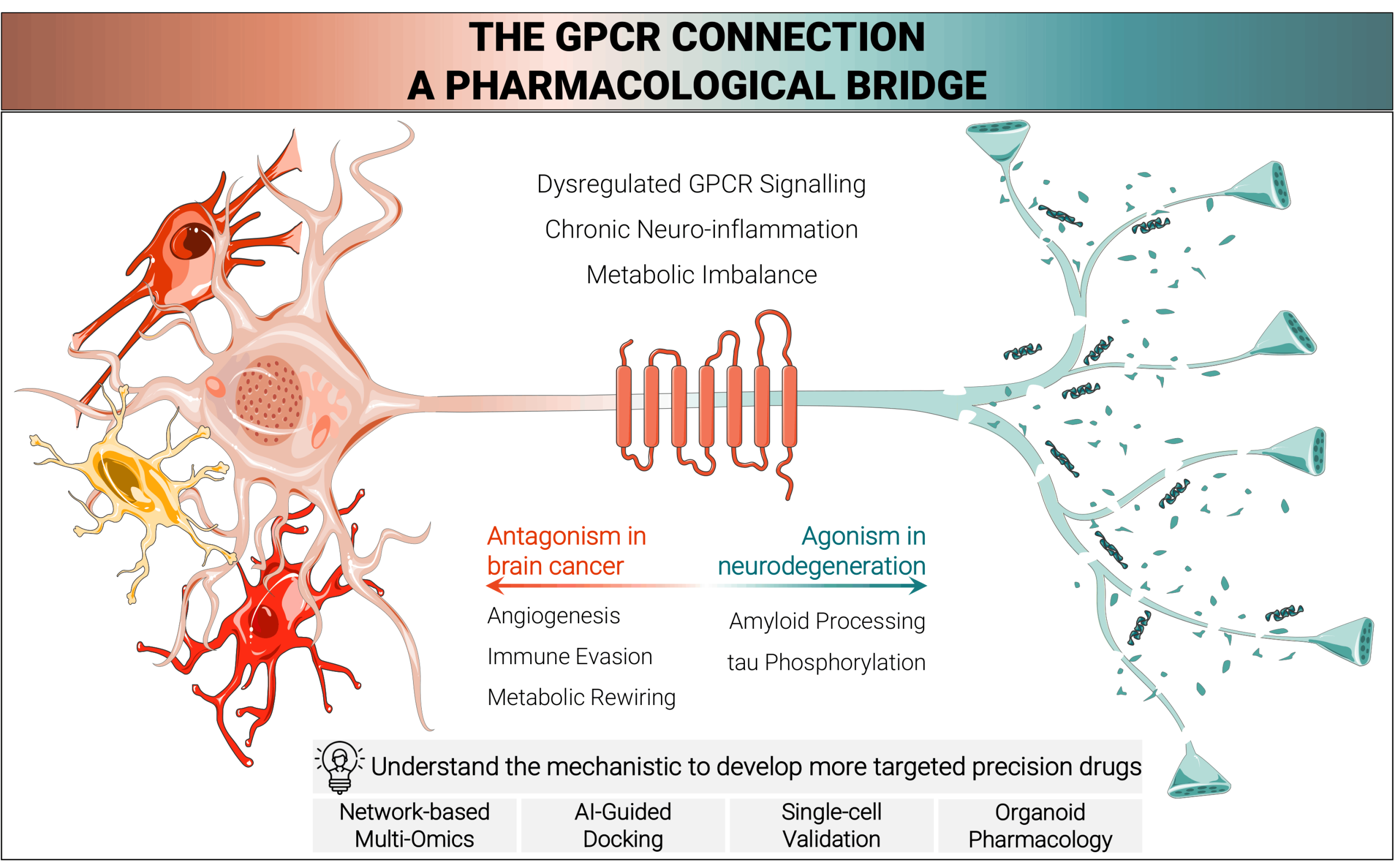
We reviewed how G protein-coupled receptors (GPCRs) shape two seemingly opposite age-related brain diseases: Alzheimer’s disease and glioblastoma.
The article shows that both disorders share dysregulated signalling networks, but the same receptors can drive either neurodegeneration or tumour growth depending on cellular context, disease stage, and ageing-related biology.
We synthesized the current literature to map the GPCR-centered pathways that link Alzheimer’s disease and glioblastoma, focusing on shared mechanisms such as inflammation, calcium imbalance, mitochondrial dysfunction, and the PI3K-AKT-mTOR and MAPK-ERK signalling axes.
We also examined how recent advances in multi-omics, AI-assisted modelling, and organoid systems are accelerating the identification and validation of druggable GPCR targets.
We wanted to move beyond viewing Alzheimer’s disease and glioblastoma as unrelated disorders and instead test whether they reflect a shared, ageing-modulated signalling architecture. This perspective helps explain why some GPCRs can be protective in one disease but pathogenic in another, and why target selection must account for context rather than receptor identity alone.
This work fits PURR.AI’s research direction because it highlights the value of integrative, data-driven, and context-aware biology for translating complex molecular knowledge into actionable therapeutic insight.
The article reinforces the importance of combining computational methods, FAIR data, and advanced disease models to prioritise precision targets in ageing-related brain disorders, aligning with PURR.AI’s strategy to build scalable, explainable, and translational AI-enabled biomedical infrastructure.
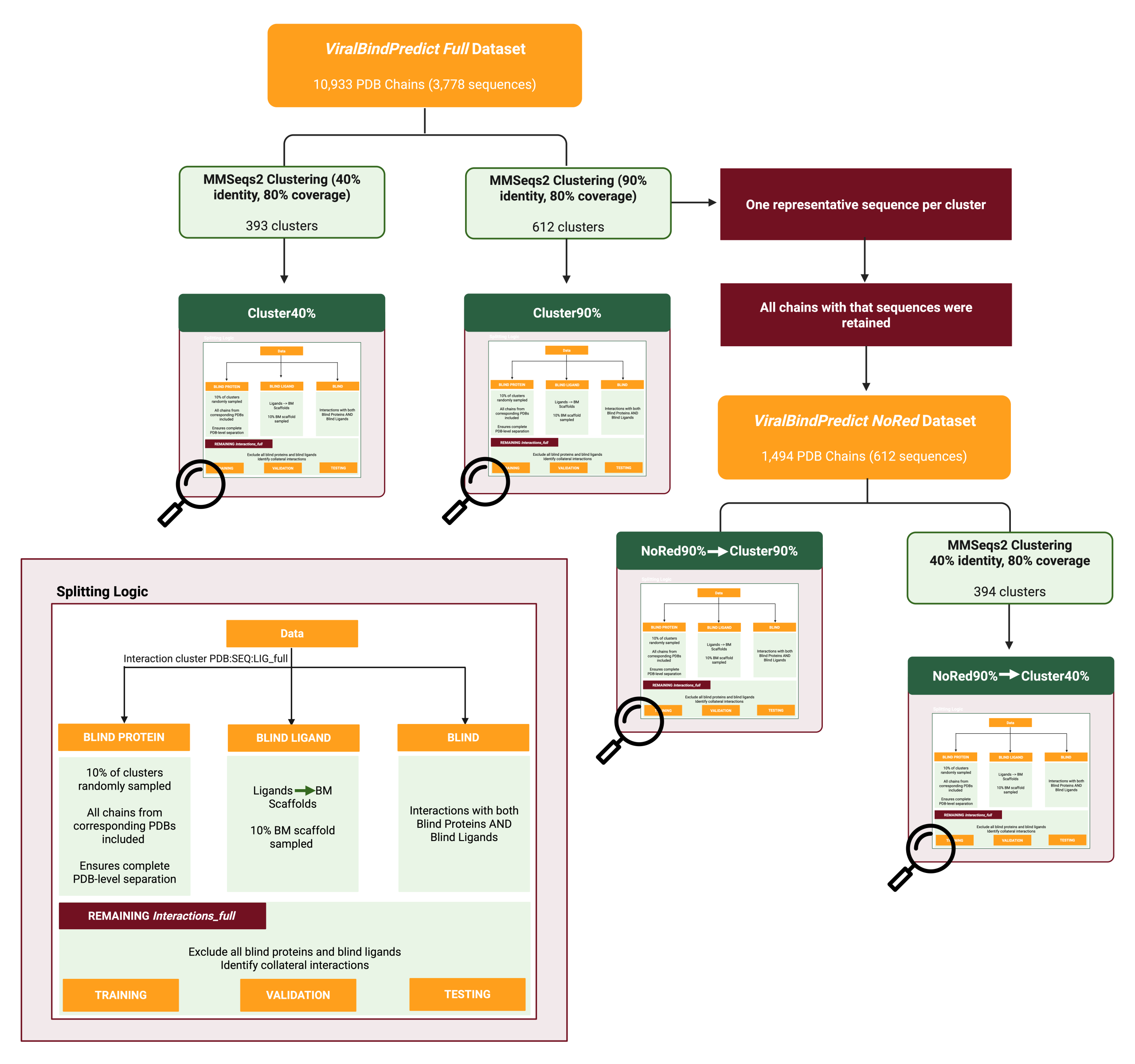
ViralBindPredict is a deep learning framework that predicts viral protein–ligand binding sites directly from sequence data. By combining curated benchmarks and advanced protein embeddings, it accelerates antiviral discovery without relying on structural models.
The team curated the first large-scale viral protein–ligand dataset (over 10,000 protein chains and approximately 13,000 interactions at a 4.5 Å threshold).
They developed MLP models using ESM2 and ProtTrans embeddings alongside Mordred descriptors. Performance was rigorously evaluated through leakage-controlled data splits (Cluster90%, NoRed90%→Cluster90%, etc.), with ESM-2 MLPs outperforming LightGBM baselines.
Traditional molecular docking approaches depend on experimentally derived viral structures—often unavailable for emerging viruses.
Even cutting-edge models such as AlphaFold struggle to achieve enough precision in binding site prediction, which hampers drug discovery, a process that can already exceed 1.8 billion USD per compound.
Viral structural proteins represent particularly promising therapeutic targets due to their unique and often low off-target characteristics. However, no sequence-based tool existed to systematically address the challenges posed by high viral mutation rates and limited structural data.
ViralBindPredict exemplifies the team’s continued expertise in developing physics- and omics-based frameworks that strengthen scientific understanding and advance the boundaries of structural bioinformatics. By demonstrating how predictive models grounded in both sequence and biophysical features can deliver robust results, this work reinforces the importance of integrating structural knowledge into antiviral research workflows.
Co-authored by researchers at PURR.AI, it also highlights the commitment to building FAIR and explainable AI platforms for viral multi-omics. These capabilities will support faster target prioritisation and compound repurposing in response to emerging viral threats, while paving the way towards integrative, equitable antiviral solutions that combine genomic, biochemical, and clinical data.
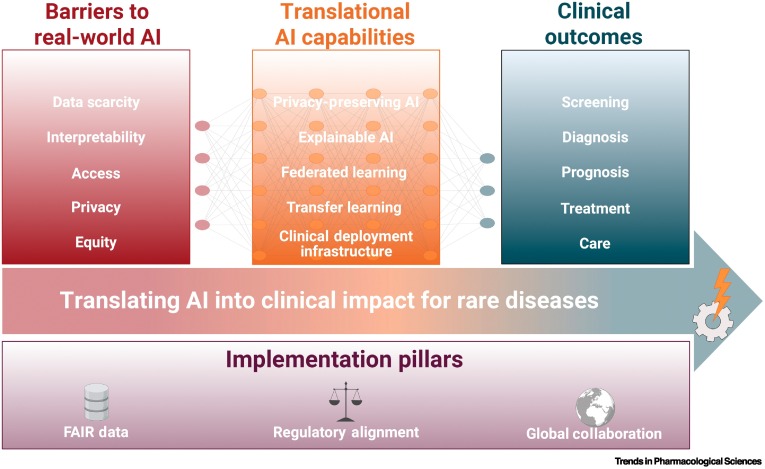
This review shows how cutting-edge artificial intelligence can transform rare disease care by accelerating diagnosis, guiding personalised treatment, and enabling faster, more efficient drug discovery.
It highlights that real clinical impact depends not only on powerful algorithms, but on high-quality FAIR data, privacy-preserving collaboration, explainable models, and globally coordinated, equity-focused infrastructures.
We systematically examined recent advances in AI for rare diseases across screening, diagnosis, prognosis, and therapy development, spanning methods such as transfer learning, generative models, federated learning, NLP, and explainable AI.
We then mapped the technical, ethical, and infrastructural priorities needed to move from proof-of-concept tools to trustworthy, integrated clinical solutions worldwide.
Despite clear promise, most AI tools for rare diseases remain fragmented and fail to reach real patients, largely due to data scarcity, bias, privacy constraints, and limited interoperability between healthcare systems.
By distilling best practices and common pitfalls, this work provides a roadmap to align innovators, clinicians, regulators, and patient communities around responsible, scalable AI adoption.
The review validates PURR.AI’s strategy of building FAIR-by-design, privacy-preserving, explainable AI platforms that integrate genomics, clinical data, and molecular knowledge for rare diseases.
It positions PURR.AI to partner as an infrastructure and analytics provider that can turn complex multi-omic data into actionable, equitable clinical insights.
GPCR‑A17 MAAP is a machine‑learning tool that predicts whether small molecules act as agonists, antagonists, or modulators across the GPCR‑A17 receptor subfamily.
It streamlines early drug discovery by replacing years of screening with rapid, high‑accuracy predictions.
We built an ensemble AI model (XGBoost, Random Forest, LightGBM) trained on 6,900 curated receptor‑ligand pairs, combining chemical descriptors with protein sequence embeddings.
The model predicts ligand function across 21 GPCR‑A17 receptors with state‑of‑the‑art accuracy (up to 0.93 F1 on Ki‑filtered datasets).
Determining how compounds interact with GPCRs has been slow, costly, and uncertain. Our model accelerates this process, enabling rational design, repurposing, and prioritisation of safer, more effective drug candidates.
GPCR‑A17 MAAP strengthens PURR.AI’s AI‑drug discovery platform by:
Reducing R&D timelines through fast, data‑driven target mapping.
Expanding discovery reach to receptors often avoided due to cost and complexity.
Improving portfolio value with more precise lead prioritisation and de‑risking of development pipelines.

This review highlights recent advances in computational and AI-driven methods for predicting drug toxicity, emphasizing the importance of drug-target binding affinity (DTBA) in anticipating adverse effects.
It surveys state-of-the-art models, key toxicity endpoints, and emerging machine learning strategies that can accelerate safer drug development and reduce reliance on animal testing.
We systematically reviewed the current landscape of computational approaches, especially artificial intelligence (AI) and machine learning (ML) models, for toxicity prediction in drug development.
This included a critical evaluation of breakthrough algorithms for major endpoints (e.g., LD50, DILI, hERG, carcinogenicity, Ames mutagenicity), as well as models for DTBA prediction—a key molecular feature in toxicity and efficacy assessment.
We compared data sources, modeling strategies, and performance metrics, providing the community with a comprehensive resource and benchmarking of current methods.
Late-stage drug attrition remains high, with unexpected toxicity being a major contributor to costly failures. Existing experimental toxicity testing is resource-intensive, time-consuming, and ethically challenging due to animal use.
By consolidating the latest computational advances—particularly in AI/ML-based toxicity and DTBA prediction—we aim to promote more accurate, rapid, and humane methods to screen drug candidates early in development. This addresses regulatory needs for safety while accelerating translation from discovery to clinic.
For PURR.AI, leveraging advanced AI methodologies in toxicity and DTBA prediction aligns perfectly with our mission to deliver smarter, more predictive molecular modeling solutions.
The approaches summarized in this review provide a scientific foundation for enhancing our platform’s safety profiling modules, reducing the risk of late-stage failures for our clients, and supporting FAIR, 3Rs-compliant research.
Integrating these state-of-the-art computational strategies positions PURR.AI at the forefront of data-driven drug discovery and predictive toxicology.
